この記事にはこんなことが書かれています。
- Pythonを使ってデータ分析をはじめよう
- 時系列データの予測をしよう
- prophetを使おう
■環境の準備
様々な環境で実行することができるが、中でも下記条件で実施することにした。
・Anacondaを使用する
・prophetのライブラリを使いたい
Anacondaはデータ分析を始める上で有益なプラットフォームとのことで選択。
Prophetは、旧Facebookが開発した時系列データを予測するライブラリで、かなり有用そうと思われたため選択。
よし、さっそくとりかかったところ数時間…
めちゃくちゃ時間がかかった。エラーが出まくった。
以下参考になればと思うので、やり方を展開します↓
※Anacondaのインストールはされていることが前提です。
ここは簡単だと思うので省略します。
まず、必要なライブラリのインストールから始めます。
ここが一番の関門でした。
ほしかったライブラリであるprophetは、pythonのバージョンを選ぶらしいです。
下記サイトを参考に旧バージョンpython 3.7.11でAnaconda上で立ち上げ。
それから下記サイトのとおり、コマンドを実行していきます
conda install libpython
conda install -c msys2 m2w64-toolchain
conda install numpy cython matplotlib pandas statsmodels scikit-learn
conda install -c conda-forge fbprophet
conda install -n base -c conda-forge jupyterlab_widgets
conda install -n Python_ex -c conda-forge ipywidgets
上記を順に実行。5分くらいかかるかな。
参考サイト
そのほか参照したこと↓
・JupiterLabを使ったことがなかったため、こちらを参照
JupiterLabで新規ファイルの作成
NewからPython3クリックで新規ファイルを作成すればよい
※もちろんPythonのプロンプトで実行でも同様の処理が可能。
■時系列データ解析テスト
環境ができたところで、時系列データを読み込み学習していこう。
下記サイトが優秀なので、これを上から実行していく
参考サイト2
で、できた・・・
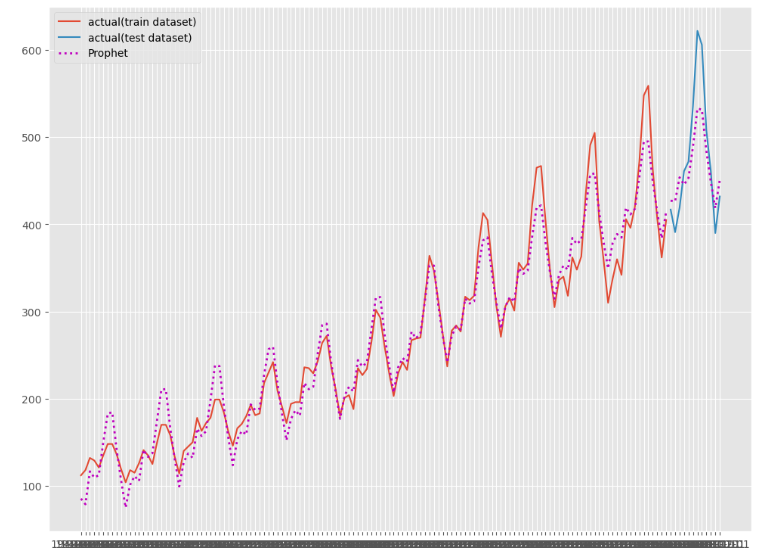
環境の構築が長かったと思いますが、ここまでできた方お疲れ様でした。
上記データ解析結果のアレンジに挑戦するなら以下を参考にが良さそう
・入力データを変えてみる
・詳細にパラメータチューニングするなら
私がでつまづいたところを記しておきます。
・Optunaが無いよ~というエラーが出た
下記サイトを参考にインストール
Optunaが無いというエラーの対処法
端的に言えば以下コマンドを実行
conda install -c conda-forge optuna
※上記サイトのとおりconda install optunaではNG
その他もっと初心者的につまづいたところは最下段で案内しています。
■その他初心者的に悩んだところ
・パッケージのインストール時に、色々やり方があること
例えば
①pip ~
②!pip ~
③conda ~
①はコマンドプロンプトで実行する時のコード
②はJupyter Notebookでの実行コード
③はAnacondaでの実行コード
エラーが出まくるので、一つずつgoogle先生に聞いてつぶしていくしかない
SSLエラー系は、管理者権限でコマンドプロンプトを起動したら直るとか
Pathの設定がおかしかったりという記事が多く、四苦八苦しながら対処した。
あとはバージョン違いだと動かないということがざらにある。
ダウングレードしたりすると解消するが、先駆者が実行した環境と同じバージョンを用意してやってみるのが最短だと思った。
それで通らないなら、別の問題がある。
試行錯誤した結果、エラーを出しながらも出力結果は問題なかったり、いつの間にか解消したり、最終的に何が良かったのかはわからないというのが多い。
・python構文で調べたところ
例として調べた構文の意味合いをメモ
【import x as y】:ライブラリを読み込んで好きな名前にリネームする
xはライブラリ名
yは自分の好きな名前
メリット:長い名前のライブラリ名を省略できる。
例:
import pandas as pd
~
df = pd.read_csv(url)
#pandasというライブラリをpdと呼び
#pdライブラリ内のread_csv()関数を使ってcsvを読み込みdfに保存
【from x import y】
x:モジュール名
y:クラス名
例:from math import pi
print(pi)
#表示は 3.141592653589793となる
#mathモジュールをインポートし、pi変数を利用
#piは円周率の値
【iloc】
ilocは行と列を「行番号」「列番号」で指定します
df_sample.iloc[0:5,0:3] ←df_sampleのテーブルから1~5行目×1~3列目を取り出し
【配列[始点:終点]】
https://qiita.com/tanuk1647/items/276d2be36f5abb8ea52e
【plt.subplots()】
軸追加する時に使う
【plt.legend()】
凡例を追加する